
When Healthcare AI Underperforms: A CFO Framework for Measuring, Documenting, and Making the Case for Better Tools
Most AI tools don't deliver what the sales rep promised. Here's how to prove it and what to do next.
Payers are spending $1 billion to $1.5 billion on AI. Health systems are deploying it across revenue cycle, clinical decision support, and prior authorization workflows. And yet inside most finance departments right now, someone is quietly re-doing the work the AI was supposed to handle — catching errors, correcting output, and adding verification steps that weren't in the original workflow design.
That is the hidden cost nobody is measuring. And it belongs on your balance sheet.
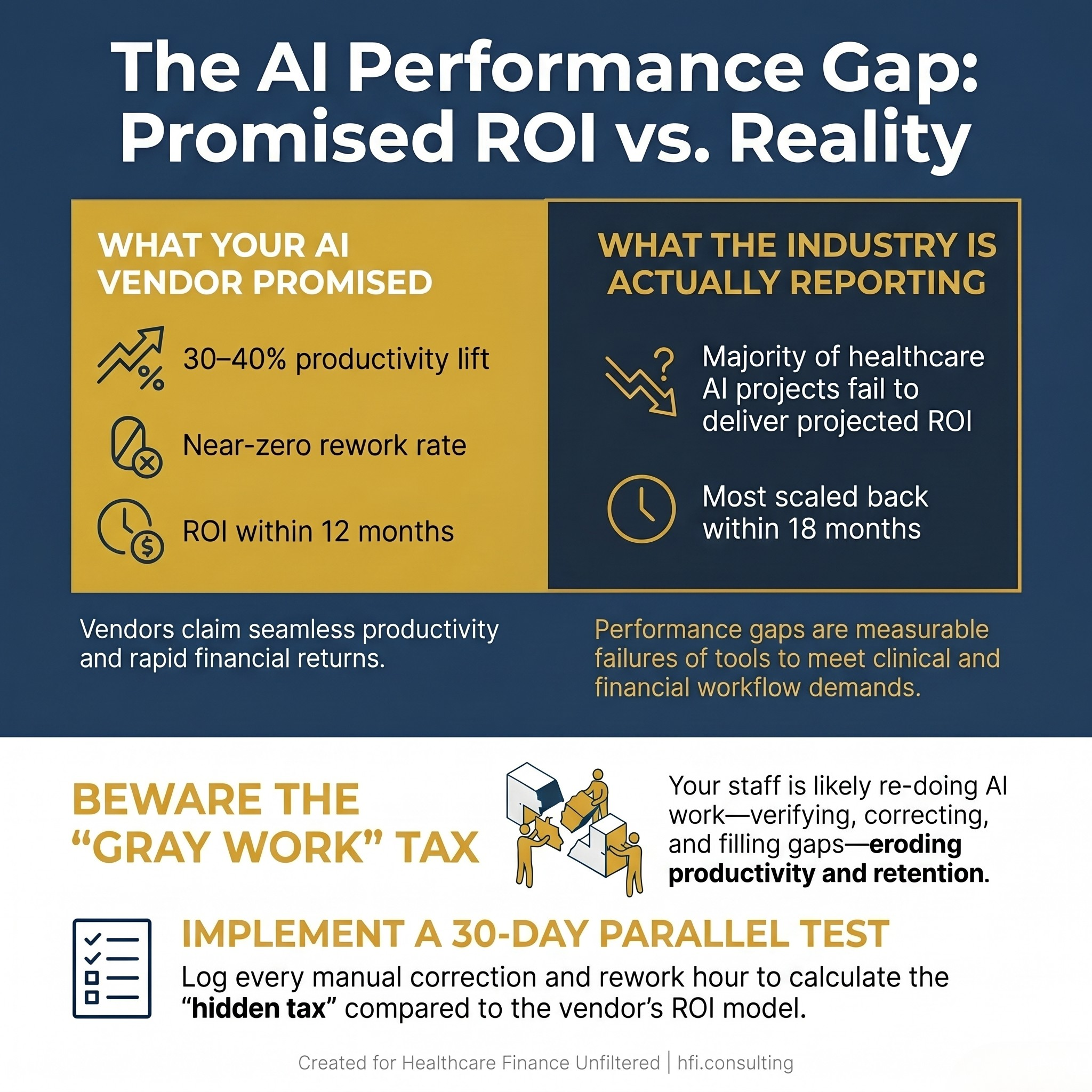
Comparison stat card showing AI vendor promises vs. reported healthcare AI ROI outcomes for CFOs
When the Tool Doesn't Match the Sale
The gap between what an AI vendor demonstrates in a pitch and what the tool actually delivers inside a live clinical or financial workflow is well-documented. A Becker's Health IT panel held at their 2026 annual meeting put a name to one of the most common failure modes: "gray work." That's the time and effort clinicians and finance staff spend verifying AI output, correcting errors, and filling gaps the tool was supposed to eliminate.
Gray work doesn't show up in your vendor's ROI model. It shows up in your productivity data — if you're measuring it.
This is not a technology problem unique to healthcare. But healthcare has amplified the stakes considerably. When clinical decision support tools produce recommendations based on expert opinion without evidence backing, as discussed at the Becker's session, patients receive unnecessary procedures and costs compound. When a revenue cycle AI flags the wrong claims or misclassifies denial categories, your team rebuilds manually — and your denial rate doesn't move.
The CFO's job is to connect those dots before the contract renews.
The Payer Side Is Moving Fast. Are Your Vendors Keeping Up?
Understanding where AI is actually performing helps you calibrate expectations on both sides of the table. Major payers are not experimenting. UnitedHealth Group and Elevance Health each disclosed tech investments in the $1 billion to $1.5 billion range, with AI central to both. Elevance reported cutting prior authorizations by nearly 70% using its Health OS platform. Optum reported 29% fewer emergency room visits and 28% fewer preventable readmissions among value-based customers using AI-driven clinical support.
Those are real results. They also represent years of iterative infrastructure investment, internal governance development, and workflow integration — not a product installed and launched in a quarter.
The implication for provider CFOs is important. Payers deploying AI at that scale are getting faster, more consistent, and more aggressive in how they manage authorizations, denials, and claims review. If your revenue cycle AI can't keep pace, you are bringing manual processes to an algorithmic fight.
For MA plan finance leaders, the picture is different. You're watching your own AI infrastructure build compete with your providers' AI adoption timeline. The asymmetry matters to your contracting strategy and your risk adjustment processes.
Why Your Staff Can't Just "Use the Tool Better"
The most common misdiagnosis when healthcare AI underperforms is treating it as a training issue or a change management problem. Sometimes those factors matter. But more often, the gap is a performance gap — and performance gaps require measurement, not sensitivity.
At the Becker's session, Dr. Harpreet Pall described what happens when tools don't fit clinical workflows: "The tools will be ignored and you'll be back where you started." That same dynamic plays out in finance departments. When the denial prediction tool generates alerts that don't match the clinical documentation your team is actually pulling, staff learn to route around it. The tool keeps running. The ROI calculation keeps assuming it's working. Nobody updates the model.
From my time managing financial operations across seven hospitals at Ascension, I watched this pattern repeat with several technology implementations. The tools that succeeded had one thing in common: someone owned a detailed current-state map before the vendor arrived, and they kept measuring the gap between that baseline and what the tool was actually producing. The implementations that failed quietly were the ones where success was assumed at go-live and never validated.
The problem is not that your staff lacks AI literacy. The problem is that your organization has not built the measurement infrastructure to tell the difference between a tool that works and a tool that looks like it works.
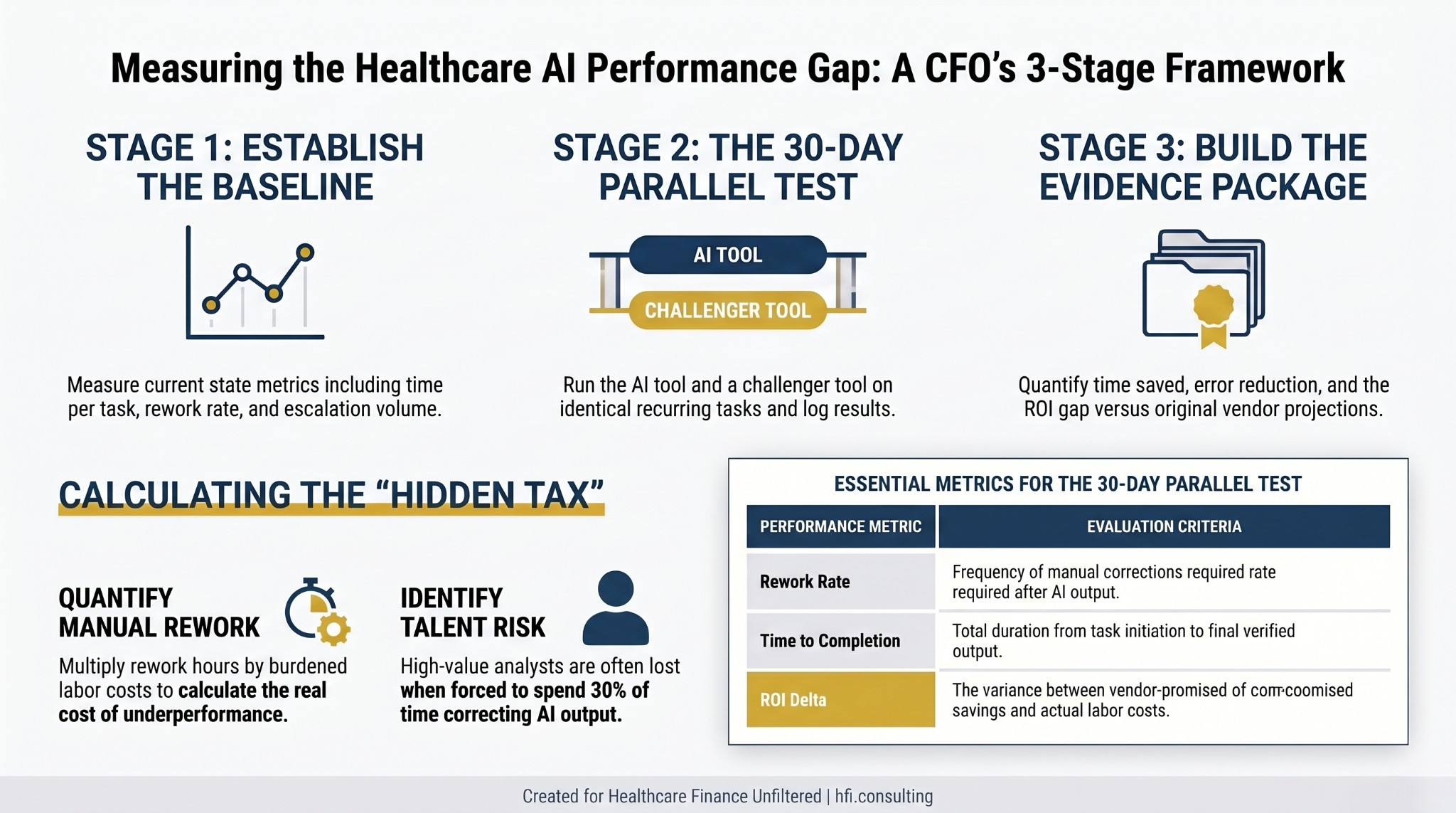
Three-stage process flow for measuring healthcare AI performance gaps against vendor projections
Building the Evidence: A Finance Leader's Measurement Protocol
The strongest case for different or better AI tooling is not a complaint. It is a log. Here is the measurement framework that turns staff frustration into boardroom-ready evidence.
Step 1: Pick one recurring, bounded task. Choose a workflow that takes 20 to 40 minutes, happens daily or weekly, and has a measurable output. Denial categorization, charge capture review, prior auth documentation assembly, and coding audit review are all strong candidates. The task needs to be specific enough that you can compare outputs directly.
Step 2: Run a parallel comparison. For 30 days, run your current tool and a challenger tool on the same task class. Log time to completion, number of corrections required, escalations generated, and error rate. You need at least 20 parallel observations to have a defensible dataset.
Step 3: Calculate the hidden tax. Multiply the average rework time per task by the number of occurrences per month. Multiply that by your burdened labor cost for the role performing the task. That number — not the vendor's ROI estimate — is your real cost of the current tool.
Step 4: Frame the ask as a routing proposal, not a replacement request. Most organizations face internal resistance to abandoning an enterprise software contract. The more successful approach is proposing a routing model: use the default tool for tasks where it performs adequately, and introduce a specialized tool for the specific subset of work where the gap is costing you measurably. This framing respects the existing investment while making a data-backed case for additive capability.
This approach sidesteps the most common objections. "We already paid for the default tool" is answered by the hidden tax calculation. The license is a sunk cost. The measurable productivity gap is a current operating expense. "This is shadow IT" is answered by the fact that you are bringing the data to leadership and proposing a structured pilot — the opposite of working around the system.
Navigating the Internal Conversation at Each Level
The evidence matters. So does knowing which argument resonates at each level of your organization.
At the manager level, the conversation is about reclaimed time. Your log of rework hours, corrections, and escalations is the primary document. A manager can approve a parallel test within an existing budget envelope without escalating.
At the director level, the conversation shifts to a pilot proposal for a specific job class. Directors can authorize a structured 60 to 90 day evaluation across a team without a capital appropriation in most organizations. The data from your 30-day test becomes the pilot design brief.
At the executive level — CFO, CIO, or CMO — the conversation is about competitive risk and talent concentration. Becker's panelists noted that talent is increasingly concentrating where tooling is excellent. If your organization's AI environment pushes your best revenue cycle analysts to spend 30% of their time correcting AI output, you will lose those analysts to organizations where the tooling performs. That is a workforce risk with a dollar value.
For CFOs presenting to the board or to IT governance committees, the framing shifts one more time. The argument is not that your AI vendor is inadequate. The argument is that your current governance structure does not have a mechanism to detect underperformance — and that building that mechanism is a finance function priority.
For a deeper look at why IT governance belongs in the finance portfolio, the IT Governance Is Now a Finance Problem piece covers the board-level risk register conversation in detail: https://rachelbarksdale.substack.com/p/it-governance-is-now-a-finance-problem?r=1077bg
What Good AI Governance Looks Like From the Finance Seat
The Becker's session framed governance as the foundation for AI trust — and trust as the precondition for AI ROI. That is exactly right from a finance perspective.
Effective AI governance in healthcare organizations includes several components that finance leaders are positioned to drive. First, a performance baseline established before deployment, not six months after. Second, an independent evaluation of whether the tool is delivering on its contractual representations — because most AI vendor contracts do not include performance guarantees that would survive legal scrutiny. Third, a human-in-the-loop requirement for any AI output that touches a billing decision, a denial determination, or a revenue projection.
The Becker's panel was emphatic that AI advisory boards should include not just clinical and IT representation, but legal counsel, data privacy specialists, and operational workflow experts. The finance office belongs in that room. You are the one modeling the ROI. You are the one who will be asked to explain the variance when projections don't land.
One practical step: build AI vendor performance review into your standard vendor management cycle. Most organizations treat AI tools like SaaS subscriptions — auto-renew until someone complains. The organizations getting the most from their AI investments treat vendor performance review as a quarterly finance function, not an IT function.
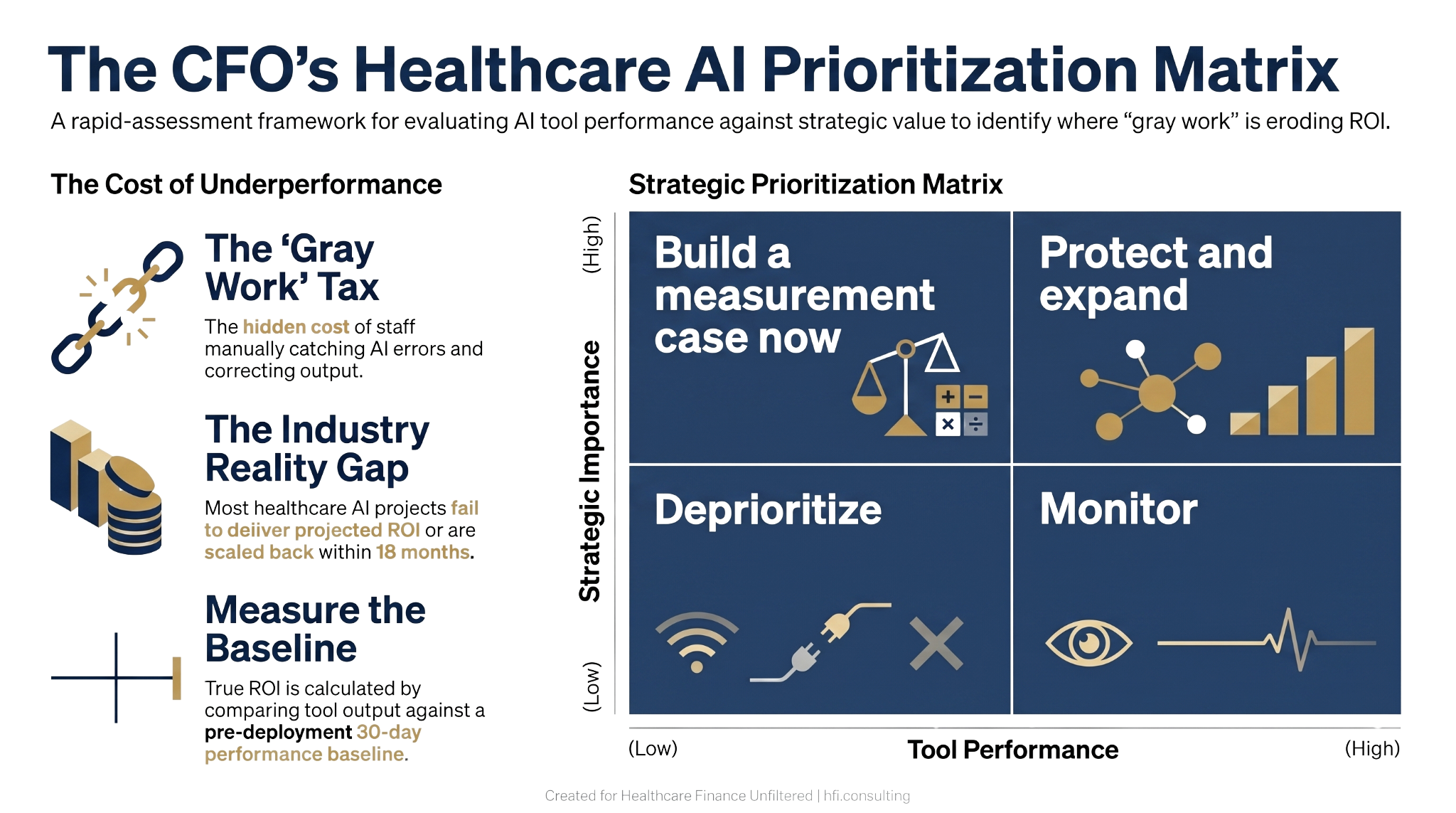
Four-quadrant decision matrix for healthcare CFOs prioritizing AI tool performance reviews by strategic importance
The Revenue Cycle Is the Testing Ground
If you want to build an internal AI performance measurement capability and are deciding where to start, revenue cycle is the right answer.
Revenue cycle AI has the clearest performance data. Denial rates, first-pass yield, days in A/R, and net revenue recovered are all measurable before and after deployment. Prior authorization processing time, clean claim rate, and charge lag are trackable at the transaction level. If your AI vendor promised a 40% reduction in denial rate and you are sitting at a 3% improvement, that gap has a dollar value you can calculate this afternoon.
The revenue cycle is also where payer AI investment creates the most immediate counterpart pressure. If your largest payer is using AI to process prior authorizations at 10x the speed your team manages them manually, your operational friction rate just went up without anyone on your staff changing their behavior. That is the environment your revenue cycle AI needs to operate in.
For a breakdown of where revenue cycle AI is actually generating documented ROI versus where it is underdelivering, the AI in the Revenue Cycle piece covers the implementation framework in detail: https://rachelbarksdale.substack.com/p/ai-in-the-revenue-cycle-how-hospitals?r=1077bg
And if you have already deployed AI and are seeing the underperformance pattern described here, the AI Automation Trap piece addresses the most common reasons healthcare AI fails at scale — and what CFOs who have walked it back are doing instead: https://rachelbarksdale.substack.com/p/the-ai-automation-trap-why-healthcare?r=1077bg
If you're working through an AI evaluation, a vendor renewal, or a board presentation on AI ROI, I work directly with health system and health plan finance leaders on exactly these questions. Visit hfi.consulting to learn more or reach out directly.
The Skill That Does Not Appear in Any Vendor Demo
There is one capability that consistently separates organizations getting real AI returns from those reporting disappointment: the ability to describe their current operational state in specific, measurable terms before any technology decision is made.
This is not a technology skill. It is a finance skill.
When you can tell a vendor exactly how many prior auth requests your team processes per day, your average handling time, your current escalation rate, and your rework rate, you have a baseline. That baseline is what makes it possible to evaluate vendor claims honestly, design a meaningful pilot, and report results with credibility.
Organizations that skip the baseline — and most do — are always in the position of arguing about whether the AI is working based on the vendor's metrics, not their own. That is a negotiation you will lose every time.
The Becker's panel captured this well: rushing to deploy AI for fear of missing out often produces organizations that go slower in the long run. Going slow at the measurement stage is what enables speed and trust at the deployment stage.
Clinical AI governance panelists put it this way: build systems that let you do great work faster by establishing principles and processes first. For finance leaders, that principle translates directly. Governance is not overhead. It is the mechanism that makes AI accountable — to your budget, to your board, and to the staff who have to use it every day.
The Talent Argument CFOs Are Not Making Yet
One dimension of the AI performance gap conversation that belongs at the executive level is workforce retention.
Revenue cycle analysts, coding specialists, and finance data professionals with strong technical skills have options. Organizations with inferior tooling that require high-value staff to spend significant time correcting AI output are effectively taxing those employees. The best ones notice. They leave for organizations where the tooling performs.
This is not a speculative risk. It is documented in the enterprise software market broadly and is beginning to appear in healthcare revenue cycle and finance specifically. If your AI environment requires skilled analysts to spend a third of their time on manual verification that the technology was supposed to eliminate, you have a talent retention risk that will not appear in your turnover report until it's too late to prevent it.
Finance leaders who bring this argument to their CIO and CHRO are making a workforce planning case that transcends any individual tool evaluation. It reframes the AI quality conversation as a strategic talent question — which is exactly the level it deserves.
When healthcare AI falls short of vendor promises, the cost isn't just frustration — it's measurable productivity loss, staff burnout, and eroding ROI. This CFO framework shows how to document the performance gap, build a data-backed case for better tools, and navigate leadership at every level. Full guide at hfi.consulting.
P.S. Quick question: Has your organization ever formally measured the rework your team performs after an AI tool generates output — or do you rely on the vendor's performance metrics? Hit reply and tell me what that measurement process looks like, or if it doesn't exist yet. I'm tracking what's actually happening in the field on this one.
If this conversation is happening in your organization and you want a structured framework for the vendor evaluation, the board presentation, or the governance design, hfi.consulting is where to start.